
PhD Research
Paradoxical replay maintains balanced and robust task representations
[Preprint] [CCN 2024 talk] [Code]
How does the brain maintain a balanced representation of different task contingencies despite experiencing them at uneven frequencies? Building on prior work that distinguishes learned task representations between “rich” and “lazy” learning, we demonstrated the crucial role of paradoxical replay in this process. Rich (contextual, task-specific) representations degrade following unbalanced experience, while lazy (task-agnostic) representations do not. However, paradoxical replay can reverse this effect, as shown in both neural network simulations and experimental data. Our findings suggest that paradoxical replay protects rich representations from the destructive effects of unbalanced experience, highlighting a novel interaction between task representations and replay in both artificial and biological systems.
Representational geometry underlying retrospective fear generalization
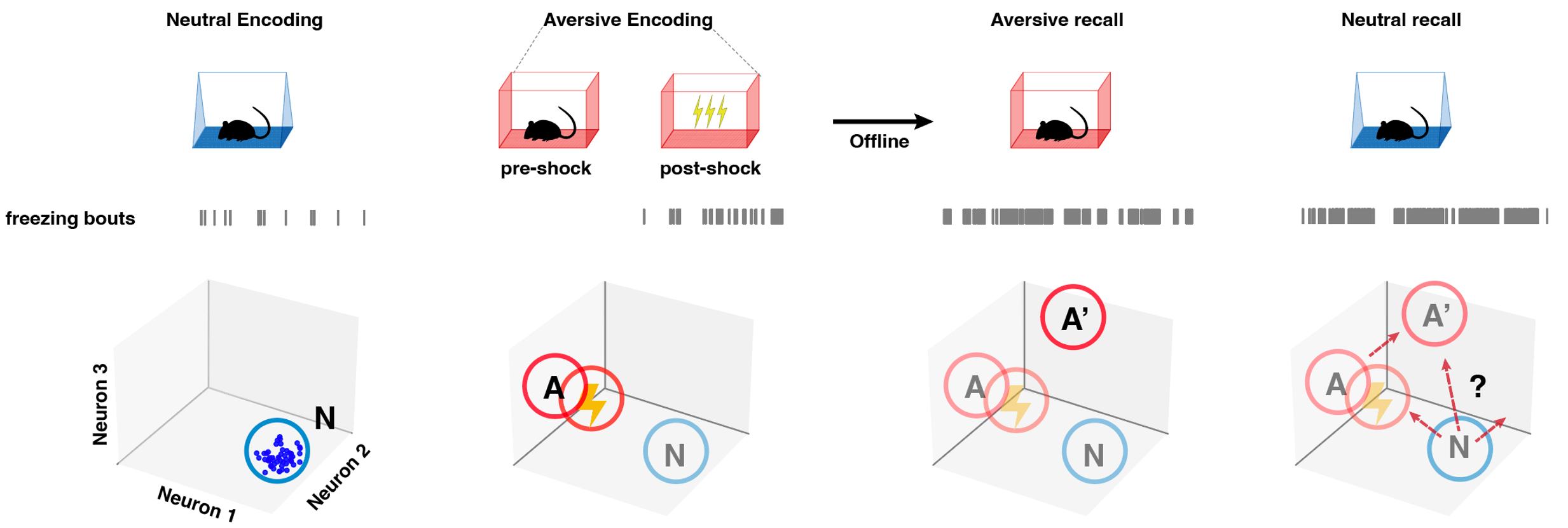
Fear generalization, a core symptom of PTSD, involves transferring fear responses from one context to another. In a recent study, mice exhibited retrospective fear generalization to a prior neutral context following aversive experiences. By investigating the neural representational geometry, we found that the neural representations of neutral and aversive contexts become more similar in fear-transferred mice. Furthermore, during freezing states, the neutral context shifts toward the aversive context; while during active exploration, neutral context activity obeyed a common fear transformation. This suggests a double dissociation in representational change related to retrospective fear generalization. Stay tuned for further details in the upcoming preprint!
Shared representational geometry in encoding of related experiences
[Curr Bio, 2021] [Featured Dispatch] [Code]
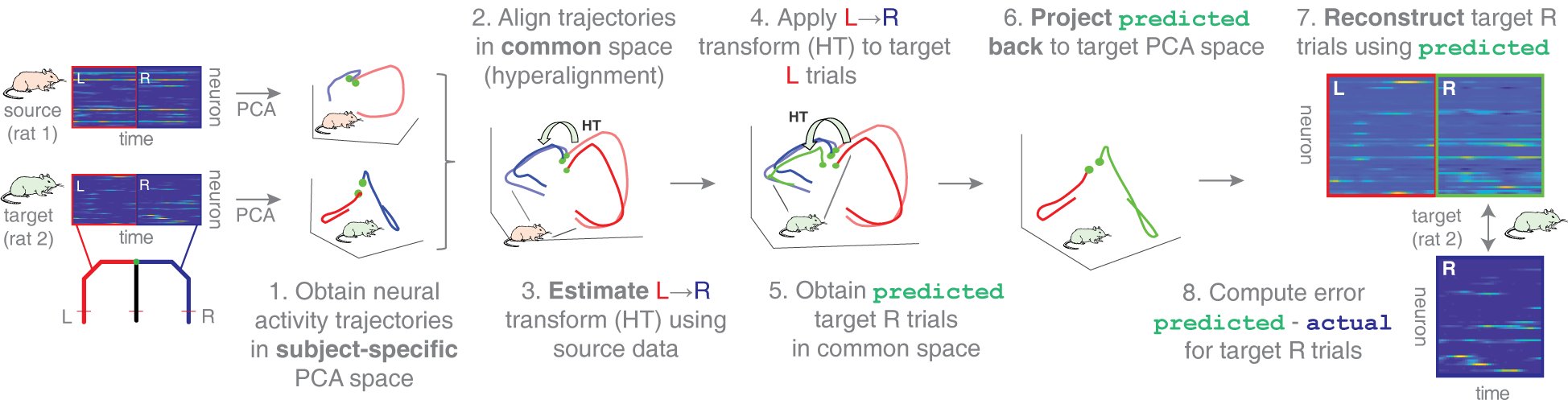
Place cells in the hippocampus form cognitive maps for spatial navigation and episodic memory. However, it’s intriguing that the brain uses distinct maps in environments with identical layouts (such as similar floors; “remapping”). Through a cross-subject alignment method, we showed that the activity of place cells in one subject can be predicted better than by chance from another subject. This suggests an alternative view that the relationship between these environments is preserved in the neural representational space and is consistent across individuals. This finding also supports the idea that hippocampal maps of different environments may be constructed based on a general rule.
Post-bac Research
Hierarchical reinforcement learning in the brain
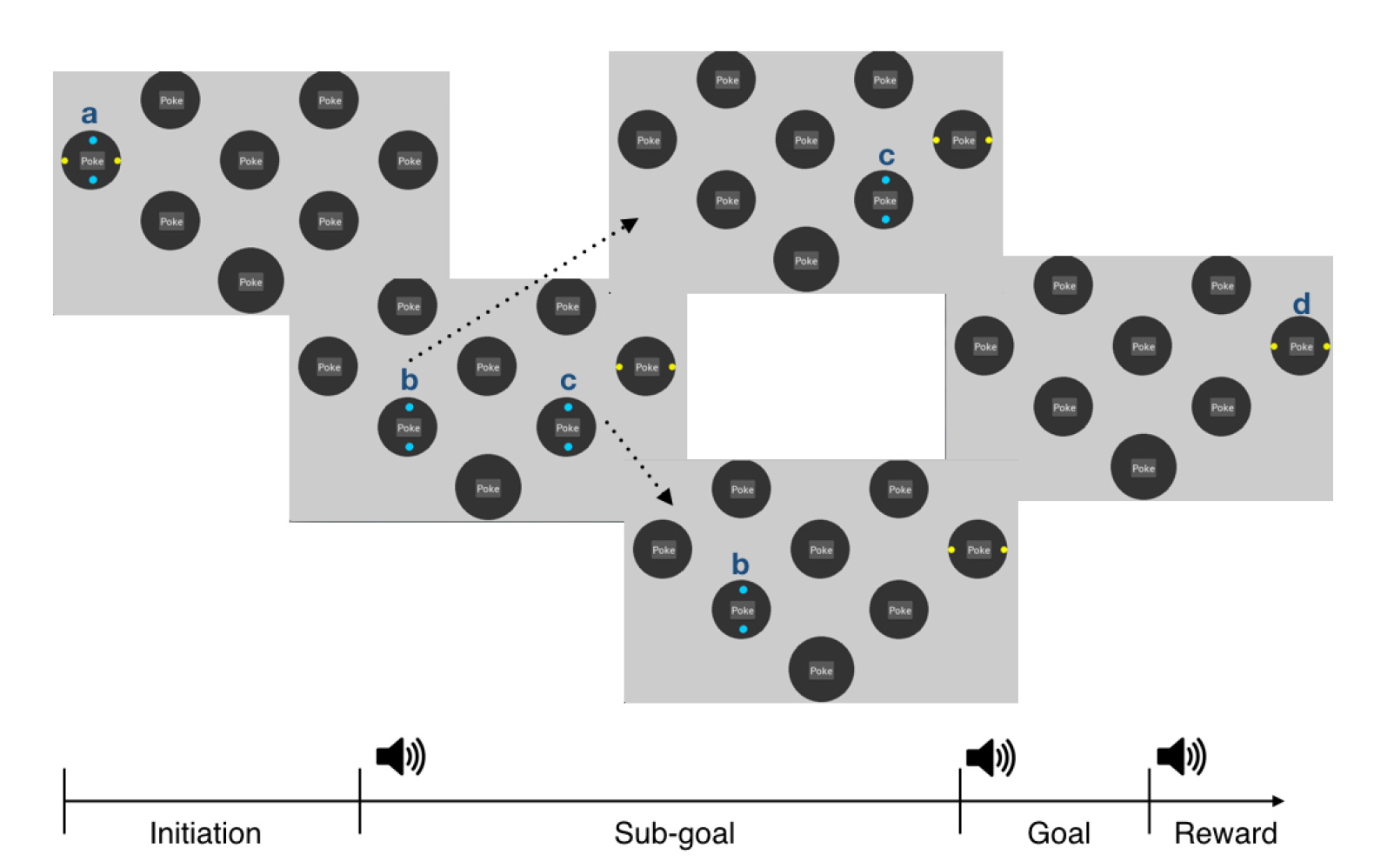
A key component of adaptive behaviors is the planning and coordination of action sequences to achieve a complex goal. The framework of hierarchical reinforcement learning hypothesizes that a complex goal can be divided into sub-goals. Correspondingly, a long sequence of actions are chunked into sub-routines for sub-goal completion, which then can be reused in a different task. For my post-bac research, I designed a rodent version of travel salesman task to study how sequences of goal-directed actions are coordinated in the brain.
Deep reinforcement learning agents
[Deep Q-learning] [Hierarchical-DQN] [Deep Policy Gradient]

Deep reinforcement learning (Deep RL) has gained widespread attention for its ability to outperform human in games like chess, go, and Atari, etc. Typically, Deep RL systems use deep neural networks to create non-linear mappings from sensory inputs to action values or action probabilities (policies) in order to maximize long-term reward. These networks are updated with error-corrected signals, often via back-propagation, to improve reward estimation and increase the frequency of highly rewarded actions. I implemented several deep reinforcement learning algorithms in Pytorch to compare with animal behaviors in a sequential decision-making task.